本科期间室友们对吴军博士的《浪潮之巅》、《数学之美》著作中毒颇深。在读完书中关于Google以及搜索引擎的章节后,被神秘的搜索引擎所吸引,于是便和室友斌踏上了搜索引擎的探索之旅!
–本文整理于16年4月,谨此纪念即将结束的大学生活
什么是搜索引擎?
搜索引擎是一种为用户提供互联网检索服务的软件系统。它根据一定的算法、调用特定的计算机程序在互联网上搜集和发现信息,在对搜集和发现的结果进行一定的加工之后形成供检索使用的数据库。对于用户而言,这种程序是在一个交互页面上,通过在输入框输入并提交关键词,系统会在数据库中进行搜索,如果找到与用户要求相匹配的网页便会以一定算法对结果进行排序,并将排序后的网页列表返回给用户。这个网页列表中的每条结果至少包括以下几个重点:
(1) 标题:提取网页标签<title></title>中的内容。
(2) URL: 统一资源定位符,即“访问地址”。
(3) 摘要:提取网页自身的meta description部分或者是网页部分比较靠前的文字部分。
用户通过浏览每条结果的简要信息,对相应结果所包含的信息进行大概判断。如果包含他所需要的信息就可以通过点击对应结果的URL来获取整个网页。
搜索引擎的历史
第一代搜索引擎
1994年,Lycos诞生,它是第一代真正的互联网搜索引擎,不过它是基于手工分类目录的,因为在当时,网站分类目录查询非常主流,大家非常熟悉的Yahoo便是其中的佼佼者。网站分类目录是由手工分类并整理,选择一些优秀的互联网网站,并进行简单的说明,分类放置到相应的目录下,用户使用这些网站的时候,通过点击一层一层的目录找到自己需要的网站。随着访问量和收录数量越来越多,Yahoo开始使用简单的数据库搜索来提高搜索效率。
第二代搜索引擎
1996出现了基于内容的第二代搜索引擎。第二代搜索引擎使用以关键词为基础的符号计算,并以关键词组合进行全文搜索和模糊搜索。与上一代相比,第二代搜索引擎拥有操作简单快捷,搜索高效直观,直接对内容进行搜索等特点,这些都是第一代搜索引擎所没有的优势。在第二代搜索引擎中,最具代表性且最成功的当属 Google,它不仅具有第二搜索引擎的全部特点,而且是基于整个互联网进行搜索的,覆盖面非常广。但是第二代搜索引擎同样也存在着缺陷,从理论上来讲,用户搜索出来的信息是使用关键词来进行匹配的,但是这又导致了它的缺陷:搜索后的结果过多,所有信息混合在一起,用户需要从结果中进行一一辨别,想要从所有结果中完全筛选完不太现实。如果想要提高搜索的准确率,就需要输入多个关键词组合提高匹配精度,进行渐进式查询。但是这样又会使搜索过程变得繁琐,降低用户体验。
第三代搜索引擎
由于第二代搜索引擎存在的应用缺陷,用户都在期待搜索效率更高、搜索结果更准确、搜索过程更方便的新一代搜索引擎的出现。第三代搜索引擎是基于自然语言的搜索,更加贴近人们的日常生活习惯,用户不必再像使用传统搜索引擎一样纠结于信息的关键字、来源、时间和作者,它可以通过用户的描述更加准确的理解用户的搜索意图,进而提供给用户所需要的信息。第三代搜索引擎的代表是 Google,它以宽广的信息覆盖率和优秀的搜索性能为发展搜索引擎的技术开创了崭新的局面。
第四代搜索引擎
随着互联网的急速发展,再加上现有硬件水平的限制,通用搜索引擎想要比较全面的获得互联网上的信息是不太现实的。这时,一种针对主题的、数据来源更广、速度更快、分类更细的搜索引擎出现了。这种搜索引擎采用特征提取和文本智能化等策略,相比前三代搜索引擎更准确有效,被称为第四代搜索引擎。
GG搜索引擎
搜索引擎的总体结构
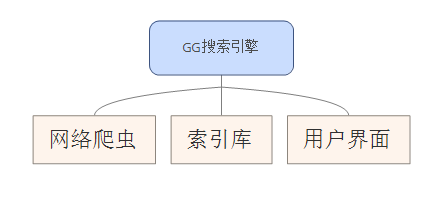
网络爬虫
网络爬虫又被称为网络机器人(Robot)或者蜘蛛(Spider),它的主要目的是获取互联网上的信息。网络爬虫能够像真人一样浏览网页,并自动的在Internet上漫游,它利用网页中的超链接遍历整个互联网,通过URL引用从一个html文档链接到另一个html文档,利用网络爬虫收集到的信息可以有很多作用,比如建立站点镜像、收集指定信息等等。
网站本身可以有两种方式声明不想被搜索引擎收录的内容:第一种是使用Robots协议,即在站点根目录下增加一个纯文本文件robots.txt,另一种方式就是直接在html页面中使用robots的meta标签。索引库
为了方便查找,早在计算机出现之前就已经有人为图书馆建立索引。
为了按词快速定位抓取过来的文档,需要以词为基础建立全文索引,将索引更新到索引数据库,索引数据库就是一个很大的查询表,主要的字段有网站名称、标题、摘要、URL地址等。对网页内容进行全文索引就是网页中的每个单词进行标引,一般来说,标引的索引词越多,检索的全面性就越高。搜索GUI
随着搜索引擎技术逐渐走向成熟,搜索用户界面也形成了一些比较固定的模式。但是最基本的功能就是为用户提供信息检索页面,并根据用户检索信息返回与之相关联的信息集合,并按照一定排序算法排序后再返回给用户。当然还有一些诸如输入提示词、相关搜索提示词、搜索热词统计等可以提升用户体验的功能
搜索引擎的设计
- 信息采集模块
- 网络爬虫的基本原理
在搜索引擎中,爬虫程序从一系列初始链接中提取网页,并把这些初始网页中的URL也提取出来,放入到URL的Todo队列之中,然后再遍历Todo队列中的URL,下载对应的网页并将网页中新发现的URL再一次放入到Todo队列之中。为了判断一个URL是否已经被访问过,将所有已经访问过的URL放入到一个Visited表中。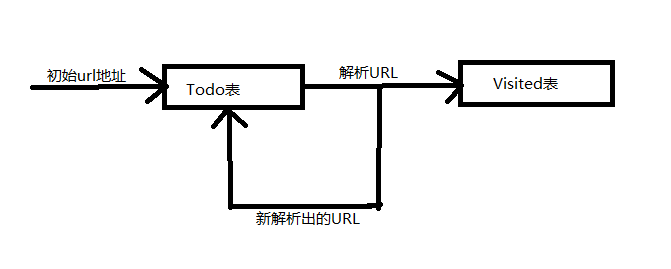
但是考虑到实际情况,为了降低爬虫程序对于内存的消耗以及爬取效率问题本系统使用了另外一套解决方案。在这个方案中, 使用Mysql数据库来存储Todo队列,将对内存消耗转换为对硬盘空间的消耗。并且在往数据库里存储URL的时候将每个URL地址 重新以MD5加密方式重新编码为一段16位的字符串,方便判断此URL是否已经被访问过。
整个互联网可以看作是一张很大图,而每个URL相当于图中的一个节点,因此,网页遍历就可以采用遍历图的算法和思路进行。网络爬虫的遍历算法通常来说有三种:深度优先遍历、广度优先遍历和最佳优先遍历。但是需要注意的是,深度优先遍历算法有一个致命的缺陷,采用深度优先遍历算法的网络爬虫很容易陷入死循环。
- 网络爬虫的基本原理
利用网络爬虫抓取网页
网络资源一般就是指Web服务器上各种格式的文件。在Java中,一旦连接上被采集的服务器,对网络资源的操作就和对本地文件操作一样简单。一般情况下,在网络中使用URL(统一资源定位符)来表示网络资源的位置。所以,通过URL就可以获得相应的网络资源。
在Java中,使用java.net.URL类就可以对URL进行建模,通过这个类,可以对指定的服务器发出请求并获得相应的文档。不过为了更加方便解析URL,在本系统中,使用了一个开源包Jsoup, 一款基于Java的html解析器,提供了类似于Jquery的操作方法来操作数据。设计数据库
在设计数据库时,本系统使用了MySQL数据库,因为MySql不仅开源而且体积小、速度快,非常适合作为本系统的数据库。
数据库是为了存储网络爬虫爬取的URL地址,将爬取URL和抓取网页分离开。数据库表link的表结构如下图:
下面对表link中的各个字段加以说明:id是表的主键,date是记录爬取链接的时间,link_md5记录的是URL以MD5方式重新编码以后的16位字符串,URL是将要抓取的网页的地址。
- 信息处理分析模块的设计
- 从HTML文件中提取文本
要想从html文件中提取文本,首先需要判断网页的编码方式,这样才能保证提取的文本不出现乱码,有时候还需要进一步识别出网页所使用的语言。因为就算是同一种编码也可能对应多种语言。识别编码的流程如下:
(1) 从Web服务器返回的content type 头信息中提取编码方式。
(2) 从网页meta标签中提取编码,如果和上一步中获得的编码方式不同,则以此处获得的编码方式为准。
(3) 如果通过上述两个步骤依然无法确定网页的编码方式,那就只有利用返回流来判断。
(4) 识别网页所使用的语言。
在确定了网页的编码方式以后,就可以提取网页中的文本信息了,网页中的文本信息主要包括网页关键字、网页描述和网页body。在下一章中将会详细的介绍怎样从网页中获得这些信息。
- 从HTML文件中提取文本
- 存储网页信息
将从网页中得到的有用信息以一定的格式存储在本地文件中,具体格式如下:
author:Bin
date:2016-03-15 11:52:50
version:1.0
title:【小游戏】小游戏大全_在线小游戏-hao123小游戏
link:http://xyx.hao123.com/
keywords:小游戏,hao123小游戏,小游戏大全,在线小游戏
description:hao123小游戏汇聚互联网热门精品小游戏,免费提供数万款在线小游戏,包括植物大战僵尸,愤怒的小鸟,连连看小游戏大全,双人小游戏大全,斗地主,益智小游戏,儿童小游戏等。 - 对信息进行分词处理
为了实现中文分词,本系统使用了一个开源jar包Lucene(一个提供了分词器和建立索引相关类的开源工具包),Lucene对中文的处理方法有三种。下面以“今天天气不错”这句话的输出结果为例:
(1) 单字方式:【今】【天】【天】【气】【不】【错】
(2) 二元覆盖的方式:【今天】【天天】【天气】【气不】【不错】
(3) 分词的方式:【今天】【天气】【不错】 - 为分词建立索引库
可以使用Lucene提供的API创建和更新索引,索引一般放在硬盘的一个路径中。索引作为一种数据结构,你可以快速随机的访问存储在里面的词,类似于字典的目录,某个词对应到某一页,查找时直接从目录里查,就不用一页一页的翻了,速度就会非常快。
- 信息查询模块的设计
- 用户搜索界面设计
在设计用户搜索界面的时候,本系统参考了目前市面上主流的搜索网站,以简单明了为设计目标。在搜索界面只有一个搜索框和一个搜索按钮,用户只需要输入想要查询信息的关键词,然后执行搜索,系统就会将搜索结果返回给用户。 - 显示结果界面设计
搜索结果由三部分组成,标题、正文和URL,在标题和正文部分,用户所搜索的关键字以高亮方式显示,在搜索结果较多时,搜索结果每页只显示10条。
搜索引擎的实现
- 信息采集模块的实现
- 网络爬虫的实现
在实现爬虫时,系统用到了Jsoup这个开源jar包,使用这个jar包只需要设置一个起始地URL地址,也就是爬虫的入口,就可以很方便的实现一个简易的网络爬虫。
为了更加方便的使用网络爬虫,系统实现一个网络爬虫的图形界面,GUI截图如下: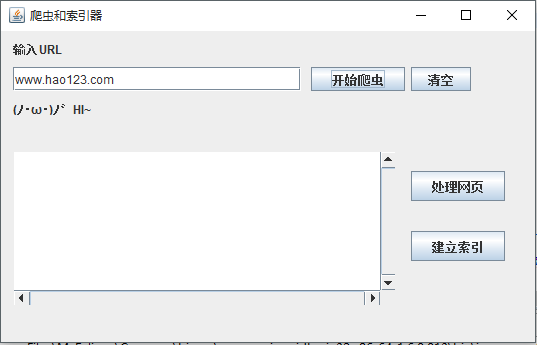
在输入一个其实URL地址之后,点击爬取按钮,网络爬虫就会像在上一章里介绍的那样开始工作,并将爬取到的URL地址存放在Mysql数据库里。
在处理过程中用到了一个MD5(一种散列函数)工具类,它具有压缩性、容易计算、抗修改性和强抗碰撞等特点。
在爬取的过程中,使用对比URL的MD5值是否在数据库中已经存在来判断此URL是否已经被访问过。 - 实现数据库
使用MySQL实现表link的sql语句如下: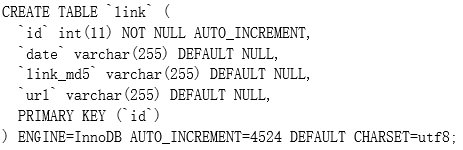
- 信息处理分析模块的实现
- 实现从HTML文件中提取文本
在上一章中已经说过,要提取文件中的文本信息,应首先提取网页的编码方式。在这里系统使用正则表达式来提取网页的编码方式。下面是根据在上一章中已经介绍过的几种情况在具体实现过程中的所使用的正则表达式:
(1)使用正则表达式从Web服务器返回的content type 头信息中提取编码方式。String regex_charset = "text/html[ ]{0,1}[Cc]harset(.*)";
(2)使用正则表达式从网页meta标签中提取编码。regex_charset = "<meta http-equiv=\"content-type\"content=\"text/html;[ ]{0,1}charset(.*?)\"[ ]{0,1}[/]{0,1}";regex_charset_spc = "<meta content=\"text/html;[ ]{0,1}charset(.*?)\"http-equiv=\"content-type\"[ ]{0,1}[/]{0,1}";
在确定了网页的编码方式后,使用正则表达式提取网页中文本信息:
(1)网页标题regex_title = "<[Tt][Ii][Tt][L1][Ee]>(.*?)</[Tt][Ii][Tt][L1][Ee]>";
(2)网页关键字regex_keywords = "<meta name=[\*]{0,1}[Kk]eywords[\"]{0,1} content=[\"]{0,1}(.*?)[ ]{0,1}[\"]{0,1}[ ]{0,1}[/]{0,1}[ ]{0,1}";
(3)网页描述String regex_des = "<meta name=[\"]{0,1}[Dd]escription[\"]{0,1}content=[\"]{0,1}(.*?)[ ]{0,1}[\"]{0,1}[ ]{0,1}[/]{0,1}[ ]{0,1}";
(4)网页body体信息regex = "<body.*?</body>" - 实现存储网页信息
将在上一节中提取到的网页的文本信息存储到本地text文件中,其存储示例如下图所示: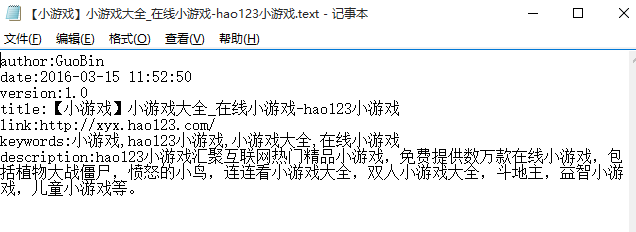
- 中文分词及建立索引库的实现
在上一章中已经提到,在进行中文分词和建立索引库的时候系统用到的是Lucene工具包。下面是使用MMAnalyzer分词器对一段话进行分词后的词库:
待分词的语句:腾讯视频电影频道提供全新热门电影免费观看,海量高清正版电影在线观看,同步更新全国视频网站热映大片,包括欧美大片,日韩电影,华语电影等。
分词后的显示结构为:
(腾讯,0,2)(视频,2,4)(电影,4,6)(频道,6,8)(提供,8,10)(全新,10,12)(热门,12,14)(电影,14,16)(免费,16,18)(观看,18,20)(海量,20,22)(高清,22,24)(正版,24,26)(电影,26,28)(在线,28,30)(观看,30,32)(同步,32,34)(更新,34,36)(全国,36,38)(视频,38,40)(网站,40,42)(热映,42,44)(大片,44,46)(包括,46,48)(欧美,48,50)(大片,50,52)(日韩,52,54)(电影,54,56)(华语,56,58)(电影等,58,61)
在上面的章节已经论述了网络爬虫的设计与实现过程,网络爬虫抓取到的文档必须经过信息处理之后才能交由进行分词和建立索引。
- 信息查询模块的实现
- 用户搜索界面的实现
搜索页面运行结果如下图所示:
- 显示结果界面的实现
下面以搜索“汽车”为例显示搜索结果,如下图所示:
可以看到,用户搜索的关键词以红色高亮显示,其它标题部分是一个可点击的链接为蓝色字体,正文部分以黑色字体显示。 - 服务器端处理过程的实现
服务器获得请求之后首先对请求和响应重新定义编码,对中文进行正确的解码,然后设置默认检索库后开始检索索引库,将关键字设置为高亮显示后将检索结果传回搜索页面显示,完成服务器端的处理。
服务器处理过程如下图所示: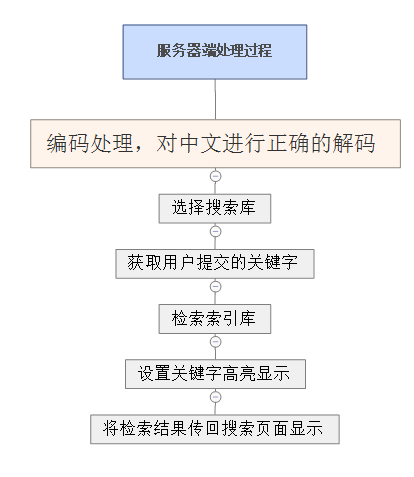
系统部署与运行
系统的客户端使用JSP实现的,所以我选择了在Tomcat上部署和运行本系统。下面是简单介绍一下系统部署过程:
在Tomcat中,应用程序的部署只需将WAR包放到Tomcat的webapp目录下。当Tomcat启动时,会自动检测并解压这个文件。当你第一次访问这个应用的时候,一般情况下会很慢,因为Tomcat需要进行一些初始化并进行编译。当然这种情况只会在第一次打开这个应用的时候出现,之后就会变得很快。另外Tomcat还内置了一个manager应用,通过这个应用,你除了可以在本地操作应用外还可以在远程的部署和撤销应用。
源码链接:SearchEngineDemo
忆往昔,曾几何时,初次踏入校园仿佛就在昨日,一夜之间添了诸多情愫,乍离别,竟多有不舍,乍暖还寒时尚最难将息,又何况共度四年的激情燃烧岁月!方寸之地历久弥坚,多年之后,感念师生恩情,同窗友谊,再顾母校,当是另一种情愫!
–吴培文离校前夕于郑州大学